Ethan Shapiro

Currently pursuing my Master of Data Science at UC Irvine with a BS in Data Science from UC San Diego. Experienced in the full data science pipeline—from data engineering and big data processing to machine learning and model deployment—gained through internships and academic research.
Passionate about leveraging big data and analytics to drive product decisions and understand user behavior. Focused on creating better user experiences through data-driven insights and product development.
View My LinkedIn Profile
Ethan Shapiro’s Portfolio
League of Legends Match Outcome Prediction (Machine Learning & Neural Networks)
Project Overview
This project predicts League of Legends match outcomes before they start by analyzing player and champion statistics to calculate win probabilities and identify key success factors. The goal was to develop a machine learning approach that could enhance matchmaking balance and improve player experience through more competitive games.
This work builds upon the DraftRec paper (DraftRec), which presented the state-of-the-art match prediction model, with modifications tailored specifically for win prediction rather than draft recommendations.
Dataset Overview
- Match History Data: 400,000+ matches, focusing on player picks, bans, and game results
- Player Performance Data: 12M+ matches, capturing in-game stats like kills, deaths, and gold earned
- Feature Engineering: Normalization, Z-scoring, and role-based differences to improve model predictions
Best Performing Models
Logistic Regression (Baseline Model)
- Accuracy: 56.04%
- Outperformed more complex models like Random Forest and XGBoost, revealing strong linear relationships in the data
Hybrid Neural Network
- Accuracy: 57.34%
- Combined deep learning (role-based strength modeling) with linear components (team stat differences), achieving the best performance
Key Findings
- Linear relationships matter – Logistic Regression outperformed many non-linear models
- Role-based skill differences are critical – Player strength in specific roles significantly impacts outcomes
- Complexity doesn’t guarantee improvement – Transformer models underperformed simpler approaches
- Hybrid architectures are effective – Combining neural networks with traditional models improved accuracy
Technical Skills & Tools
Skills: Machine Learning, Neural Networks, Data Cleaning, Feature Engineering, Model Evaluation
Tools: Python, PyTorch, Riot API, AWS EC2, Scikit-Learn
Steam Review Sentiment Analysis (Big Data & NLP)
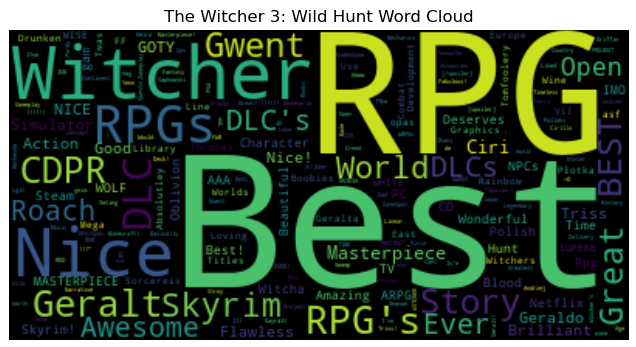
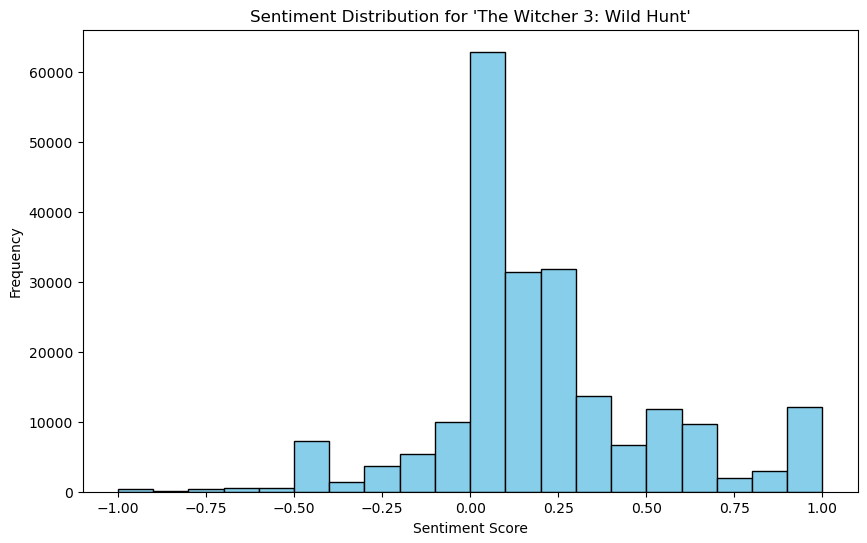
Project Overview: Analyzed a 35GB Steam reviews dataset using PySpark to extract sentiment insights and perform entity recognition at scale. This project demonstrates proficiency in distributed computing, natural language processing, and handling large-scale unstructured data.
Implemented advanced PySpark techniques including optimized partitioning, efficient joins, and distributed computation to process millions of reviews. Applied NLP pipelines using PySpark NLP and John Snow Labs’ library for entity recognition with pre-trained models, and performed unsupervised sentiment analysis using TextBlob and clustering algorithms to identify patterns in player feedback.
Technical Skills & Tools
Skills: Big Data Processing, Natural Language Processing (NLP), Entity Recognition, Sentiment Analysis, Distributed Computing
Tools: Python, PySpark, PySpark NLP, John Snow Labs NLP, TextBlob
Soft Decision Trees Research Project (Interpretable AI & Feature Learning)
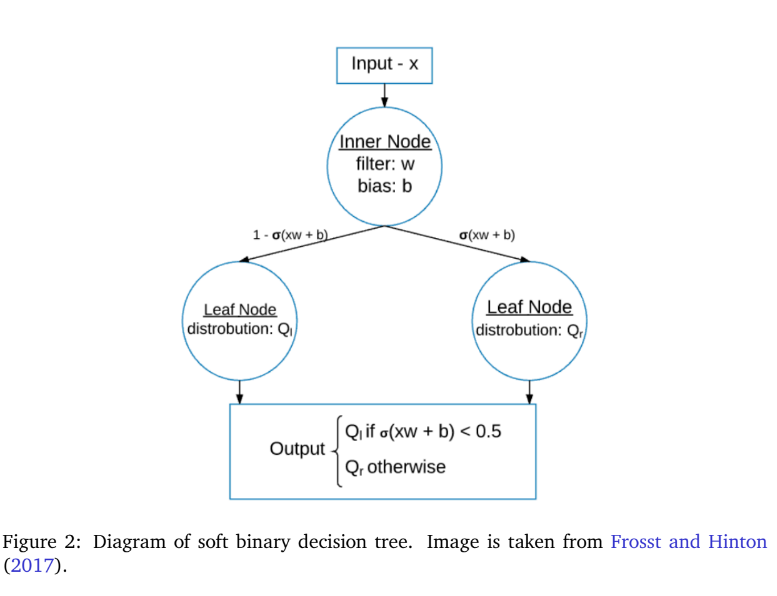
Project Overview: Conducted academic research on soft decision trees (SDTs) to improve machine learning interpretability while maintaining high performance. Unlike traditional decision trees with binary splits, SDTs use probabilistic decisions to handle ambiguity more effectively. This research focused on feature learning techniques and the Neural Feature Matrix (NFM) for visualizing learned features.
Validated the approach on MNIST and CelebA datasets, demonstrating that SDTs match neural network accuracy while providing interpretable decision paths. Successfully identified key facial features in the complex CelebA dataset, validating SDTs’ real-world applicability. Achieved an 8% accuracy improvement by integrating SDT-learned features into a neural network within the same training epochs.
The findings demonstrate SDTs’ potential to combine neural network flexibility with decision tree transparency, making them valuable for applications requiring interpretable AI such as medical diagnostics and financial modeling.
Technical Skills & Tools
Skills: Matrix Calculus, Neural Networks, Soft Decision Trees, Feature Learning, Data Visualization, Research & Academic Writing
Tools: Python, PyTorch, MNIST, CelebA
Fantasy League of Legends (Full-Stack Development & ML Deployment)
Project Overview: Built a full-stack fantasy sports application that predicts League of Legends match outcomes based on player selections. This end-to-end project demonstrates proficiency in backend development, frontend design, machine learning deployment, and comprehensive testing practices.
Developed a CRUD backend in Go to handle API requests between the frontend and prediction model. Created an interactive single-page application using Next.js deployed on Firebase for seamless user experience. Collected and processed data from the Riot API, trained a PyTorch prediction model, and deployed it to AWS Lambda for scalable, serverless inference. Implemented comprehensive testing with Cypress (frontend), Testify (backend), and PyTest (ML API) to ensure reliability across all system components.
Technical Skills & Tools
Skills: Full-Stack Development, Machine Learning Deployment, API Development, Data Collection, Testing & QA
Tools: Python, PyTorch, AWS Lambda, S3, Firebase, Next.js, Go, Cypress, PyTest, Google Cloud Run, Riot API